問題タブ [bayesian]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
statistics - AI/色の名前を決定するための統計的手法
あらかじめ決められた候補のリストから、(RGB値)の色の名前を推測するための小さなライブラリを作成することを考えています。
私の最初の試みは、純粋に3次元RGB色空間内のピタゴリアン距離に基づいていました-名前の付いた色点のほとんどが空間の端にあったため(たとえば、0、0、255の青)、これは大した成功ではありませんでした。 、スペースの中央にあるほとんどの色では、最も近い名前の色もかなり恣意的でした。
だから、私はより良いアプローチを考えていて、いくつかの候補を考え出しました
HSV色空間内の円柱距離-上記と同様の問題が発生する可能性がありますが、HSVは、RGBよりも人間的な意味で意味があるように思われます。これは便利です。
上記のいずれかですが、名前が付けられた各カラーポイントは、周囲の空間内のポイントへの引力の強さを示す任意の値で重み付けされています。そのようなモデルの名前はありますか?これは少し漠然としていると思いますが、私にはかなり直感的なアイデアのようです。
HSV色のプロパティを調べて、最も可能性の高い色名を返すベイジアンネットワーク(たとえば、P(黒|彩度<10)、P(赤|色相= 0)に似たノードを想像していますが、これは理想的とは言えません-たとえば、特定の色が赤になる確率は、離散値ではなく、色相が0にどれだけ近いかに比例します。ベイジアンネットワークを適応させて、テストされている変数?
最後に、HSVまたはRGB色空間内のサポートベクターマシンベースの分類があるかどうか疑問に思っていましたが、これらにあまり精通していないため、これがピタゴラス距離ベースのアプローチよりも特別な利点を提供するかどうかはわかりません。特に私は3次元空間しか扱っていないので、最初に試しました。
したがって、私は疑問に思っていました、あなたの誰かが同様の問題の経験を持っているか、または私がアプローチを決定するのを助けることができるかもしれないリソースを知っていますか?誰かが私を正しい方向に向けることができれば(それが上記のいずれかであろうと、まったく異なるものであろうと)、私は非常に感謝しています。
乾杯!
ティム
algorithm - 自動タグ付けのための質問アナライザーの実装
質問アナライザーを実装するための適切なリソースは何ですか?
技術者以外のユーザーが質問しやすくするために、質問に自動タグを付ける方法を見つけようとしています。ベイズ定理を使用してこれを達成できることがわかりましたが、実装方法がわかりません。
これに関するオープンソースのライブラリや研究論文はありますか?
algorithm - 評価ごとに複数のカテゴリを持つベイジアン評価システム
私は自分の Web サイトで使用する評価システムを実装していますが、ベイジアン平均が最適な方法だと思います。すべてのアイテムは、ユーザーによって 6 つの異なるカテゴリで評価されます。ただし、評価の高いアイテムが 1 つしかないアイテムをトップに押し上げたくはありません。そのため、ベイジアン システムを実装したいと考えています。
式は次のとおりです。
アイテムは 6 つの異なるカテゴリで評価されるため、これらのカテゴリの合計の平均をベイジアン システムの「this_rating」として使用する必要がありますか? たとえば、2 つの評価 (0 ~ 5 のスケール) を持つ 1 つのアイテムを取り上げます。
「this_rating」は単に上記の合計の平均であるべきですか? 私の考えは正しいですか、それとも各カテゴリにもベイジアン システムを実装する必要がありますか (またはそれは考えすぎですか)。
php - ベイズ分類器の PHP 実装: トピックをテキストに割り当てる
私のニュース ページ プロジェクトには、次の構造を持つデータベース テーブルnewsがあります。
さらに、単語の頻度に関する情報を含むテーブルベイがあります。
ここで、PHP スクリプトですべてのニュース エントリを分類し、いくつかの可能なカテゴリ (トピック) の 1 つをそれらに割り当てたいと考えています。
これは正しい実装ですか?改善できますか?
トレーニングは手動で行われ、このコードには含まれていません。「不動産を売ればお金を稼ぐことができる」というテキストがカテゴリ/トピック「経済」に割り当てられている場合、すべての単語 (you,can,make,...) が「経済」のテーブルベイに挿入されます。トピックと 1が標準カウントです。単語が同じトピックとの組み合わせで既に存在する場合、カウントがインクリメントされます。
サンプル学習データ:
単語のトピック数
カチンスキー 政治 1
ソニーテクノロジー1
銀行経済学1
電話技術 1
ソニー経済学3
エリクソンテクノロジー2
サンプル出力/結果:
テキストのタイトル: 電話テスト Sony Ericsson Aspen - 敏感な Winberry
政治
....電話 ....テスト ....ソニー ....エリクソン ....アスペン ....センシティブ ....ウィンベリー
テクノロジー
....phone FOUND ....test ....sony FOUND ....ericsson FOUND ....aspen ....sensitive ....winberry
経済
....電話 ....test ....sony FOUND ....ericsson ....aspen ....sensitive ....winberry
結果: テキストはトピック Technology に属し、可能性は 0.013888888888889 です。
事前にどうもありがとうございました!
c# - Twitter の感情分析プロジェクト用に、C# でオープン ソースの単純なベイジアン分類子を探しています
ここで同様のプロジェクトを見つけました:Sentiment analysis for Twitter in Python。ただし、私は C# に取り組んでおり、同じ言語でオープン ソースの単純なベイジアン分類子を使用する必要があります。同じ目標を達成するためにpython Bayesian Classifierを利用する方法を誰かが明らかにできない限り。何か案は?
python - 特定のアプリケーション向けのベイジアン ネットワークの Pythonic 実装
これが、私がこの質問をしている理由です。 昨年、特定のタイプのモデル (ベイジアン ネットワークで記述) の事後確率を計算する C++ コードをいくつか作成しました。このモデルはうまく機能し、他の人が私のソフトウェアを使い始めました。今、私は自分のモデルを改善したいと考えています。私はすでに新しいモデル用にわずかに異なる推論アルゴリズムをコーディングしているので、ランタイムはそれほど重要ではなく、Python を使用するとよりエレガントで扱いやすいコードを作成できる可能性があるため、Python を使用することにしました。
通常、このような状況では、Python で既存のベイジアン ネットワーク パッケージを検索しますが、使用している推論アルゴリズムは独自のものであり、Python の優れた設計についてさらに学ぶ絶好の機会になると考えました。
ネットワーク グラフ用の優れた Python モジュール (networkx) を既に見つけました。これにより、各ノードと各エッジに辞書をアタッチできます。基本的に、これにより、ノードとエッジのプロパティを指定できます。
特定のネットワークとその観測データについて、モデル内の割り当てられていない変数の可能性を計算する関数を作成する必要があります。
たとえば、従来の「アジア」ネットワーク ( http://www.bayesserver.com/Resources/Images/AsiaNetwork.png ) では、「XRay Result」と「Dyspnea」の状態がわかっているため、関数を記述する必要があります。他の変数が特定の値を持つ可能性を計算します (モデルに従って)。
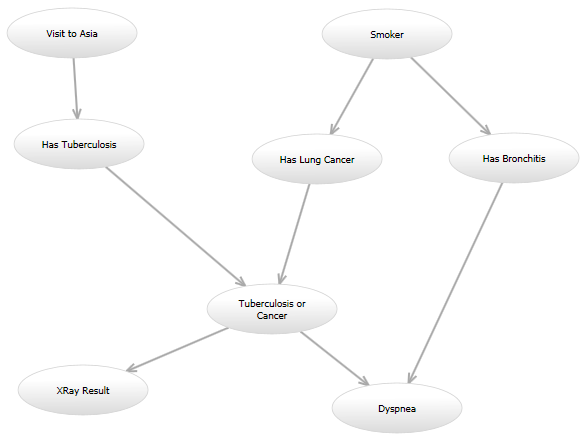{kind=link}
これが私のプログラミングに関する質問です。 いくつかのモデルを試してみるつもりですが、将来的には別のモデルを試してみたいと思うかもしれません。たとえば、1 つのモデルがアジア ネットワークとまったく同じように見える場合があります。別のモデルでは、「Visit to Asia」から「Has Lung Cancer」に有向エッジが追加される場合があります。別のモデルは元の有向グラフを使用する場合がありますが、「結核または癌」ノードと「気管支炎あり」ノードが与えられた場合、「呼吸困難」ノードの確率モデルは異なる場合があります。これらのモデルはすべて、異なる方法で尤度を計算します。
すべてのモデルにはかなりの重複があります。たとえば、「Or」ノードに入る複数のエッジは、すべての入力が「0」の場合は常に「0」になり、それ以外の場合は「1」になります。ただし、モデルによっては、ある範囲の整数値を取るノードを持つものもあれば、ブール型のものもあります。
過去に、私はこのようなことをプログラムする方法に苦労しました。うそをつくつもりはありません。かなりの量のコードをコピーして貼り付けており、1 つのメソッドの変更を複数のファイルに反映する必要がある場合がありました。今回は、これを正しい方法で行うために時間を費やしたいと思っています。
いくつかのオプション:
- 私はすでにこれを正しい方法で行っていました。最初にコーディングし、後で質問します。コードをコピーして貼り付け、モデルごとに 1 つのクラスを作成する方が高速です。世界は暗く無秩序な場所です...
- 各モデルは独自のクラスですが、一般的な BayesianNetwork モデルのサブクラスでもあります。この一般的なモデルは、オーバーライドされるいくつかの関数を使用します。Stroustrup は誇りに思うでしょう。
- 異なる尤度を計算する同じクラスにいくつかの関数を作成します。
- 一般的な BayesianNetwork ライブラリをコーディングし、このライブラリによって読み取られる特定のグラフとして推論の問題を実装します。ノードとエッジには、"Boolean" や "OrFunction" などのプロパティを指定する必要があります。これらは、親ノードの既知の状態を考慮して、さまざまな結果の確率を計算するために使用できます。これらのプロパティ文字列 ("OrFunction" など) を使用して、適切な関数を検索して呼び出すこともできます。おそらく数年後には、1988 年版の Mathematica に似たものを作ることになるでしょう!
どうもありがとうございました。
更新: ここではオブジェクト指向のアイデアが大いに役立ちます (各ノードには、特定のノード サブタイプの先行ノードの指定されたセットがあり、各ノードには、先行ノードの状態などを考慮して、さまざまな結果状態の可能性を計算する尤度関数があります。 )。おっと!
java - Ruby コードを Java に変換する
Ruby を使用したことはありませんが、このコードを Java に変換する必要があります。
誰でも私を助けることができますか?
これはRubyのコードです。
ここから入手したので、そこに何か手がかりがあるかもしれません。平均の計算について
これが解決策でした。万が一、必要な方がいらっしゃいましたら
python - Biopython へのラプラシアン平滑化
Bioinformatics プロジェクトの Biopython のナイーブ ベイズ コード1にラプラシアン スムージング サポートを追加しようとしています。
ナイーブ ベイズ アルゴリズムとラプラシアン スムージングに関する多くのドキュメントを読みましたが、基本的な考え方は理解できたと思いますが、これをそのコードと統合することはできません (実際、どの部分に 1 -ラプラシアン数を追加するかわかりません)。
私は Python に詳しくなく、初心者のコーダーです。Biopython に詳しい方からアドバイスをいただければ幸いです。
c# - テキスト著者識別のためのベイジアン分類
C# を使用して独自のテキスト作成者識別システムを構築することに興味があります。これを達成するには、おそらく何らかのタイプのベイジアン分類アルゴリズムを使用する必要があると思います。
これと同様のことを行うリソースまたは既存のライブラリを知っている人はいますか?