問題タブ [infobright]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
mysql - 分析のためのデータベース
受信データから統計レポートを生成する大規模なデータベースをセットアップしています。
システムは、ほとんどの場合、次のように動作します。
- 約400k〜500k行(約30列、主にvarchar(5-30)と日時)が毎朝アップロードされます。フラットファイル形式では約60MBですが、適切なインデックスを追加すると、DB内で急激に増加します。
- 当日のデータから様々な統計が生成されます。
- これらの統計からのレポートが生成され、保存されます。
- 現在のデータセットは、パーティション化された履歴テーブルにコピーされます。
- エンドユーザーは、定数ではなくフィールド間の関係を含む可能性が高い情報について、1日を通して現在のデータセット(コピーされたものであり、移動されていないもの)を照会できます。
- ユーザーは履歴テーブルから特殊な検索を要求できますが、クエリはDBAによって作成されます。
- 翌日のアップロードの前に、現在のデータテーブルは切り捨てられます。
これは基本的に、既存のシステムのバージョン2になります。
現在、MySQL 5.0 MyISAMテーブルを使用しており(Innodbはスペース使用量だけで殺害していました)、#6と#4で大きな苦しみを味わっています。#4は、5.0でサポートされていないため、現在、パーティションテーブルではありません。レコードを履歴に挿入するのにかかる膨大な時間(時間と時間)を回避するために、インデックス付けされていないhistory_queueテーブルに毎日書き込み、次に最も遅い時間の週末にキューを書き込みます。履歴テーブル。問題は、その週に生成された履歴クエリがその週に数日遅れている可能性があることです。履歴テーブルのインデックスを減らすことができないか、そのクエリが使用できなくなります。
次のリリースでは、少なくともMySQL 5.1(MySQLを使用している場合)に確実に移行しますが、PostgreSQLを強く検討しています。議論が終焉を迎えたことは知っていますが、この状況に関連するアドバイスはないかと思いました。研究のほとんどは、Webサイトの使用を中心に展開しています。インデックス作成は実際にはMySQLの主な機能であり、PostgreSQLは部分インデックスと関数に基づくインデックスを介して私たちを助けてくれるようです。
私は2つの違いについて何十もの記事を読みましたが、ほとんどは古いものです。PostgreSQLは長い間「より高度ですが遅い」とラベル付けされてきました-それでも一般的にMySQL5.1とPostgreSQL8.3を比較する場合ですか、それとも現在はよりバランスが取れていますか?
商用データベース(OracleおよびMS SQL)は、単にオプションではありません。Oracleがそうだったらいいのにと思います。
MyISAMとInnodbについての注意:Innodbを実行していたのですが、3〜4倍遅いなど、はるかに遅いことがわかりました。しかし、私たちはMySQLにもかなり慣れていて、率直に言って、dbがInnodb用に適切に調整されているかどうかはわかりません。
バッテリーバックアップ、フェイルオーバーネットワーク接続、バックアップジェネレーター、完全冗長システムなど、非常に高い稼働時間の環境で実行しています。そのため、MyISAMの整合性に関する懸念が考慮され、許容できると見なされました。
5.1に関して:5.1に関連する安定性の問題を聞いたことがあります。一般的に、最近(過去12か月以内)のソフトウェアは安定していないと思います。5.1で更新された機能セットは、プロジェクトを再設計する機会を考えると、手放すには多すぎます。
PostgreSQLの落とし穴に関して:where句のないCOUNT(*)は、私たちにとって非常にまれなケースです。これが問題になるとは思いません。COPY FROMは、LOAD DATA INFILEほど柔軟ではありませんが、中間のロードテーブルで修正されます。私の最大の懸念は、INSERTIGNOREの欠如です。複数のレコードを2回入れて、最後に巨大なGROUP BYを実行して重複を削除する必要がないように、処理テーブルを作成するときによく使用します。私はそれがそれの欠如が許容できるほどまれにしか使用されていないと思います。
hadoop - 無料のデータウェアハウス-Infobright、Hadoop / Hive、または何ですか?
大量の小さなデータオブジェクト(1か月あたり数百万行)を保存する必要があります。それらが保存されると、変更されません。する必要がある :
- 安全に保管してください
- それらを分析に使用します(主に時間指向)
- 時々生データを取得する
- JasperReportsまたはBIRTで使用できると便利です
私の最初のショットはInfobrightCommunityでした-MySQLの列指向の読み取り専用保存メカニズムです
一方、人々はNoSQLアプローチの方が良いかもしれないと言います。Hadoop + Hiveは有望に見えますが、ドキュメントは貧弱に見え、バージョン番号は1.0未満です。
Hypertable、Pentaho、MongoDBについて聞いたことがあります...。
何かお勧めはありますか?
(はい、ここでいくつかのトピックを見つけましたが、それは1、2年前でした)
編集:その他のソリューション:MonetDB、InfiniDB、LucidDB-どう思いますか?
data-warehouse - データウェアハウスの日時ディメンション
データウェアハウスを構築しています。それぞれの事実にはそれがありtimestampます。日、月、四半期ごとにレポートを作成する必要がありますが、時間ごとにも作成する必要があります。例を見ると、日付はディメンションテーブルに保存される傾向があることがわかります。(ソース:etl-tools.info)
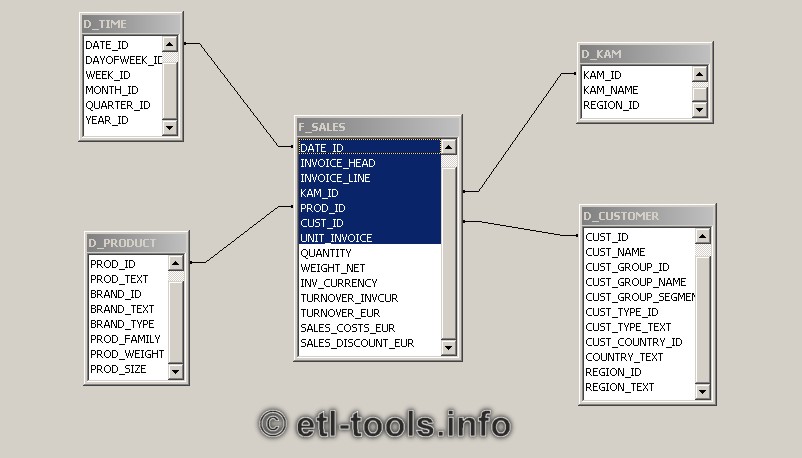{kind=link}
しかし、私はそれが時間の意味をなさないと思います。ディメンションテーブルはどんどん大きくなります。一方、日付ディメンションテーブルを使用したJOINは、で日付/時刻関数を使用するよりも効率的ですSQL。
あなたの意見/解決策は何ですか?
(私はInfobrightを使用しています)
java - Javaからinfobrightにアクセスする
誰かがJavaからInfobrightにアクセスするための技術を教えてくれませんか。私が理解している限り、休止状態のような高レベルのものを使用するのではなく、プレーンなjdbc接続を使用してクエリを実行する必要があります。私は正しいですか?
mysql - Infobright Enterprise Edition (IEE) サービスが開始されませんか?
www.infobright.com にアクセスし、Infobright Enterprise Edition (IEE) をダウンロードしてインストールしました。ただし、サービスは開始されず、エラーの内容と理由についてのヒントはまったくありません。
performance - 列指向と行指向のデータベースを混在させていますか?
私は現在、Webアプリケーションのパフォーマンスを改善しようとしています。アプリケーションの目的は、を提供すること(real time) analyticsです。star schemaいくつかのファクトテーブルと多くのディメンションテーブルに類似したデータベースモデルがあります。データベースはMysqlとMyIsamエンジンで実行されています。
ファクトテーブルのサイズは簡単に数百万を超える可能性があり、一部のディメンションテーブルも数百万に達する可能性があります。
ここで重要なのは、ディメンションテーブルがファクトテーブルに結合され、集計が行われると、selectクエリが非常に遅くなる可能性があるということです。これを聞いて最初に頭に浮かぶのは、データを事前に計算してみませんか?ユーザーは自由にカスタマイズ可能な複数のフィルターを使用できるため、これは不可能です。
ですから、私が必要としているのは、あらゆる目的に適したオールインワンシステムです;)残念ながら、それはまだ発明されていませんでした。そこで、2つの既存のシステムを組み合わせるというアイデアにたどり着きました。row orientedaとcolumn orientedデータベースの混合(例:infinidbまたはinfobright)。mysql MyIsamソリューション(高速挿入および行ベースのクエリ用)を維持し、列指向データベース(いくつかの列での高速集計操作用)を追加し、cronjobを介して定期的に(毎晩)入力します。問題は、現在のデータ(リアルタイムである必要があります)が照会される場合です。したがって、両方のデータベースからデータを取得する必要があり、複雑になる可能性があります。
infinidbを使用した最初のテストでは、いくつかの列の集計で非常に優れたパフォーマンスが示されたため、これがアプリケーションの高速化に役立つと思います。
だから問題は、これは良い考えですか?誰かがすでにこれを行ったのでしょうか?たぶんそれを行うためのより良い方法があります。
私はまだ列指向データベースの経験がなく、そのスキーマがどのように見えるかもわかりません。最初のテストでは、同じstar schema like構造だけでなく構造でも良好なパフォーマンスが示されましたbig table like。
この質問がSOに当てはまるといいのですが。
mysql - perl を介して infobright DB に接続する方法は?
perl を介して infobright DB に接続する方法は?
mysql - InfoBright ICE でのデータの読み込みに問題がある
ICE バージョン: infobright-3.5.2-p1-win_32
大きなファイルを読み込もうとしていますが、次のようなエラーの問題が発生し続けます。
データまたは列の定義が間違っています。行: 989、フィールド: 5。
これは行 989、フィールド 5 です。
”(450)568-3***”
注:最後の 3 文字も数字ですが、ここに誰かの電話番号を掲載したくありませんでした。
その分野の他のエントリとまったく違いはありません。
そのフィールドのデータ型は VARCHAR(255) NOT NULL です
jasper-reports - Jasper Reports で複数の mysql クエリを実行するにはどうすればよいですか (あなたの考えではありません...)
ランクを必要とする複雑なクエリがあります。これを行う標準的な方法は、このページhttp://thinkdiff.net/mysql/how-to-get-rank-using-mysql-query/にある手法を使用することであることがわかりました。バックエンドとして Infobright を使用していますが、期待どおりに動作しません。つまり、標準の MySQL エンジンではランクが 1、2、3、4 などと表示されますが、Brighthouse (Infobright のエンジン) は 1、1、1、1 などを返します。変数、関数を設定し、クエリで実行する戦略。まさにそれを行う概念実証クエリを次に示します。
次に、関数をコピーして Jasper Report の iReport に貼り付け、レポートをコンパイルしました。実行後、構文エラーが発生します。だから私はおそらくそれを考えました; 捨てていました。そのため、クエリの先頭に DELIMITER ; を挿入しました。これもうまくいきませんでした。
私がやりたいことは可能ですか?もしそうなら、どのように?また、関数を記述せずにランクを取得する Infobright の方法があれば、それも受け入れます。
rdbms - infobrightの列の最大数
現在約45列のinfobrightテーブルに数十億行を格納しています。さらに50列を追加します。これらの列を追加すると、読み取りのパフォーマンスが低下しますか?これらの列の新しいテーブルを作成する方が良いオプションですか?または、infobrightは列指向のデータベースであるため、50列を追加してもそれほど重要ではありませんか?
ありがとう!