問題タブ [neural-network]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
c++ - C++ は、shared_ptr を hash_map キーとしてブーストします
私はニューラル ネットワークを作成しており、各ニューロンの出力ニューロンの重み参照を保持するために hash_map を使用したいと考えていました。
boost::shared_ptr を stdext::hash_map のキーとして使用できないことに気付いたので、別の提案は何でしょうか? 回避策はありますか、または別のキーを使用するか、std::map に切り替える唯一のオプションですか? ありがとう!
エラーは次のとおりです。
java - Joone 対 Encog - 本番アプリ
本番アプリケーションで Joone と Encog の両方を使用した人はいますか? 製品が不足している製品アプリで何かする必要がありましたか?
statistics - 目的関数による多変量マッピング/回帰
概要
次元 N の「入力」の多変量時系列があり、これを次元 M (M < N) の出力時系列にマップしたいと考えています。入力は [0,k] に制限され、出力は [0,1 ]。一連のタイム スライスの入力ベクトルを「 I[t]」、出力ベクトルを「O[t] 」と呼びましょう。
ペア<I[t], O[t]>の最適なマッピングがわかっていれば、標準的な多変量回帰/トレーニング手法 (NN、SVM など) のいずれかを使用して、マッピング関数を発見できます。
問題特定の<I[t], O[t]>
ペア
間の関係はわかりませんが、むしろ、出力時系列の全体的な適合性についての見解を持っています。つまり、適合性は完全な出力系列のペナルティ関数によって管理されます。
マッピング/回帰関数 " f "を決定したいのですが、ここで:
ペナルティ関数 P(O) が最小化されるように:
[ペナルティ関数 P は、 fをI[t] に複数回適用して生成された結果の系列に適用されていることに注意してください。つまり、fはI[t]の関数であり、時系列全体ではありません]
I と O の間のマッピングは非常に複雑であるため、どの関数がその基礎を形成する必要があるのか わかりません。したがって、多くの基底関数を試してみる必要があります。
これにアプローチする 1 つの方法について意見を持っていますが、提案に偏りはありません。
アイデア?
machine-learning - 「学習率」を選択して調整するための良い方法が必要
下の図では、目的の出力(赤い線)を生成することを学習しようとしている学習アルゴリズムを見ることができます。学習アルゴリズムは、後方エラー伝播ニューラルネットワークに似ています。
「学習率」は、トレーニングプロセス中に行われる調整のサイズを制御する値です。学習率が高すぎる場合、アルゴリズムは迅速に学習しますが、その予測はトレーニングプロセス中に大きくジャンプします(緑色の線-学習率0.001)。低い場合、予測のジャンプは少なくなりますが、アルゴリズムは学習時間がはるかに長くなります(青い線-学習率0.0001)。
黒い線は移動平均です。
学習率を調整して、最初は目的の出力に近づくように収束させ、その後、正しい値に焦点を合わせることができるように速度を落とすにはどうすればよいですか?
学習率グラフhttp://img.skitch.com/20090605-pqpkse1yr1e5r869y6eehmpsym.png
{kind=link}
neural-network - ニューラル ネットワーク トレーニング用のデータセット
人工ニューラルネットワークのさまざまなトレーニング方法をテストおよび比較するための比較的単純なデータセットを探しています。入力と出力のリストの入力形式 (0-1 に正規化) に変換するためにあまり前処理を必要としないデータが必要です。リンクを歓迎します。
reverse-engineering - 逆コンパイラ用のANN?
逆コンパイルで人工ニューラル ネットワークを利用する試みはこれまでにありましたか? ソースのトリミングされたセマンティクスをコードと共にニューラル ネットワークに提供して、2 つの間の接続を学習できるようにできれば素晴らしいと思います。これは、最適化が行われるとその効果が失われる可能性が高く、高級言語でもうまく機能する可能性があると思いますが、誰かがこれを試みたことがあれば聞いてみたいです.
python - ニューラルネットの入出力
チーム統計、天気、サイコロ、複雑な数値タイプなどのより複雑なデータセットを行う方法を誰か説明してもらえますか
私はすべての数学とすべてがどのように機能するかを理解していますが、より複雑なデータを入力する方法と、それが吐き出すデータを読み取る方法がわからないだけです
誰かがPythonで例を提供できれば、それは大きな助けになります
matlab - Matlab - ニューラル ネットワークのトレーニング
バックプロパゲーションを使用した 2 層ニューラル ネットワークの作成に取り組んでいます。NN は、各行に次の情報を保持する 20001x17 ベクトルからデータを取得することになっています。
-最初の 16 個のセルには、0 から 15 までの範囲の整数が格納されており、変数として機能し、これらの変数を見たときにアルファベットの 26 文字のどれを表現するかを決定するのに役立ちます。たとえば、次のような一連の 16 個の値は、文字 A を表すことを意味します: [2 8 4 5 2 7 5 3 1 6 0 8 2 7 2 7]。
-17 番目のセルには、必要なアルファベットの文字を表す 1 から 26 までの数字が入ります。1 は A、2 は B などを表します。
NN の出力層は 26 個の出力で構成されます。NN に上記のような入力が与えられるたびに、入力値が表す文字に対応する 1 つのセルを除くすべてにゼロを含む 1x26 ベクトルを出力することになっています。たとえば、出力 [1 0 0 ... 0] は文字 A になり、[0 0 0 ... 1] は文字 Z になります。
コードを提示する前に重要なこと: traingdm 関数を使用する必要があり、隠しレイヤーの番号は (今のところ) 21 に固定されています。
上記の概念を作成しようとして、次の matlab コードを作成しました。
ここで私の問題:出力を説明どおりにしたい、つまり、たとえば y2 ベクトルの各列は文字の表現にする必要があります。私のコードはそうしません。代わりに、0 と 1 の間、値が 0.1 から 0.9 の間で大きく変化する結果が生成されました。
私の質問は次のとおりです。私がしていない変換を行う必要がありますか? つまり、入力および/または出力データを、NN が正しく学習しているかどうかを実際に確認できる形式に変換する必要がありますか?
任意の入力をいただければ幸いです。
artificial-intelligence - 畳み込みニューラルネットワーク-特徴マップを取得する方法は?
畳み込みニューラルネットワークに関する本や記事を数冊読んだのですが、その概念は理解しているようですが、下の画像のようにどのように配置すればよいかわかりません:(
出典:what-when-how.com)
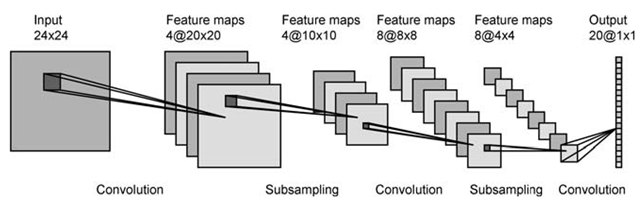{kind=link}
28x28の正規化されたピクセルINPUTから、サイズ24x24の4つの特徴マップを取得します。しかし、それらを取得する方法は?INPUT画像のサイズを変更しますか?または画像変換を実行しますか?しかし、どのような変換ですか?または、入力画像を24x24 x4コーナーの4つのサイズにカットしますか?プロセスがわかりません。各ステップで画像を切り取ったり、サイズを小さくしたりしているようです。おかげで助けてください。