問題タブ [percentile]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
mysql - MySQLでパーセンタイルランクを計算する
MySQLには非常に大きな測定データのテーブルがあり、これらの値のすべてのパーセンタイルランクを計算する必要があります。Oracleにはpercent_rankという関数があるようですが、MySQLに似たものは見つかりません。確かに、Pythonでブルートフォース攻撃を行うことができます。これは、とにかくテーブルにデータを入力するために使用しますが、1つのサンプルに200.000の観測値がある可能性があるため、これは非常に非効率的だと思います。
algorithm - ライブ データ キャプチャのパーセンタイル
ライブ データ キャプチャのパーセンタイルを決定するアルゴリズムを探しています。
たとえば、サーバー アプリケーションの開発を考えてみましょう。
サーバーの応答時間は、17 ミリ秒 33 ミリ秒 52 ミリ秒 60 ミリ秒 55 ミリ秒などです。
90 パーセンタイル応答時間、80 パーセンタイル応答時間などをレポートすると便利です。
単純なアルゴリズムは、各応答時間をリストに挿入することです。統計が要求されたら、リストをソートし、適切な位置で値を取得します。
メモリ使用量は、リクエスト数に比例して増加します。
限られたメモリ使用量で「おおよその」パーセンタイル統計を生成するアルゴリズムはありますか? たとえば、何百万ものリクエストを処理する方法でこの問題を解決したいとしますが、パーセンタイルの追跡には 1 キロバイトのメモリしか使用したくないとします (パーセンタイルが想定されているため、古いリクエストの追跡を破棄することはオプションではありませんすべてのリクエストに適用されます)。
また、分布のアプリオリな知識がないことも必要です。たとえば、事前にバケットの範囲を指定したくありません。
python - python/numpy でパーセンタイルを計算するにはどうすればよいですか?
シーケンスまたは 1 次元の numpy 配列のパーセンタイルを計算する便利な方法はありますか?
Excel のパーセンタイル関数に似たものを探しています。
NumPy の統計リファレンスを調べましたが、これが見つかりませんでした。私が見つけたのは中央値 (50 パーセンタイル) だけで、より具体的なものは見つかりませんでした。
matlab - MATLAB で 99% のカバレッジを計算するには?
MATLAB に行列があり、各列の 99% の値を見つける必要があります。つまり、母集団の 99% がそれよりも大きな値を持つような値です。このためのMATLABの関数はありますか?
excel - データ リスト自体の代わりに「バケット」データを使用して Excel でパーセンタイルを計算する
特定のパーセンタイル情報を取得する必要がある Excel のデータがたくさんあります。問題は、データセットを各値で構成する代わりに、データの数または「バケット」に関する情報を持っていることです。
たとえば、実際のデータ セットが 1,1,2,2,2,2,3,3,4,4,4 のようになっているとします。
私が持っているデータセットは次のとおりです。
要約データを完全なデータ セットに展開することなく、パーセンタイル情報 (および中央値) を計算する簡単な方法はありますか? (これを行うと、Percentile(A1:A5, p) 関数を使用できることがわかります)
私のデータセットは非常に大きいため、これは重要です。データを展開すると、数十万行になり、数百のデータセットに対してそれを行う必要があります。
ヘルプ!
mysql - MySQL から n パーセンタイルを選択
単純なデータ テーブルがあり、クエリから約 40 パーセンタイルにある行を選択したいと考えています。
最初にクエリを実行して行数を見つけてから、n 番目の行を並べ替えて選択する別のクエリを実行することで、今すぐこれを行うことができます。
93、93*0.4 = 37 のような値を返す場合があります。
これら 2 つのクエリを 1 つのクエリに結合できますか?
algorithm - パーセンタイルを繰り返し計算するための高速アルゴリズム?
アルゴリズムでは、値を追加するたびにデータセットの75パーセンタイルを計算する必要があります。今私はこれをやっています:
- 価値を得る
x x並べ替え済みの配列の後ろに挿入しますx配列がソートされるまでスワップダウンします- 位置にある要素を読み取ります
array[array.size * 3/4]
ポイント3はO(n)で、残りはO(1)ですが、特に配列が大きくなると、これはまだかなり遅くなります。これを最適化する方法はありますか?
アップデート
ニキータありがとう!私はC++を使用しているので、これは実装が最も簡単なソリューションです。コードは次のとおりです。
c# - 外れ値を削除するためにパーセンタイルを計算するための高速アルゴリズム
さらに処理する前に外れ値を削除するために、データセットのおおよそのパーセンタイル(順序統計量)を繰り返し計算する必要があるプログラムがあります。私は現在、値の配列を並べ替えて適切な要素を選択することでこれを行っています。これは実行可能ですが、プログラムのかなりマイナーな部分であるにもかかわらず、プロファイルの目立ったブリップです。
より詳しい情報:
- データセットには最大100000の浮動小数点数が含まれ、「合理的に」分散されていると想定されます。特定の値の近くで密度が重複したり、大きなスパイクが発生したりする可能性はほとんどありません。また、何らかの奇妙な理由で分布が奇妙な場合は、データがとにかく混乱し、さらに処理が疑わしいため、近似の精度が低くても問題ありません。ただし、データは必ずしも均一または正規分布しているとは限りません。退化する可能性は非常に低いです。
- 近似解は問題ありませんが、それが有効であることを確認するには、近似がどのようにエラーを引き起こすかを理解する必要があります。
- 外れ値を削除することが目的なので、常に同じデータに対して2つのパーセンタイルを計算しています。たとえば、1つは95%、もう1つは5%です。
- アプリはC#であり、C++では少し手間がかかります。擬似コードまたはいずれかの既存のライブラリで問題ありません。
- 外れ値を削除するまったく異なる方法も、合理的である限り問題ありません。
- 更新:おおよその選択アルゴリズムを探しているようです。
これはすべてループで実行されますが、データは毎回(わずかに)異なるため、この質問で行ったようにデータ構造を再利用するのは簡単ではありません。
実装されたソリューション
Gronimが提案したウィキペディア選択アルゴリズムを使用すると、実行時間のこの部分が約20分の1に短縮されました。
C#の実装が見つからなかったので、これが私が思いついたものです。Array.Sortよりも小さな入力でも高速です。そして1000要素でそれは25倍速くなります。
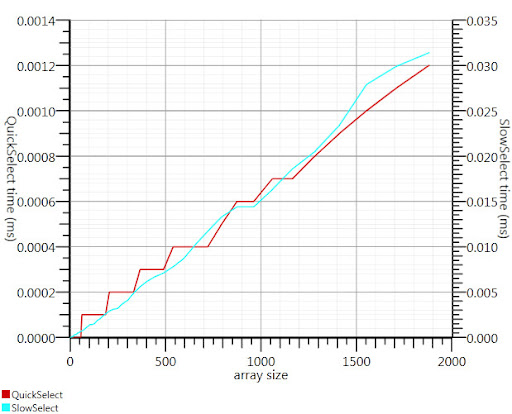
グロニム、私を正しい方向に向けてくれてありがとう!