問題タブ [zipf]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
python - テキスト内の単語頻度の最適な zipf 分布を計算する方法
宿題のために、テキストの単語の頻度をプロットし、それを最適なzipf分布と比較する必要があります。
ログロググラフのランクに従って、テキストのカウントされた単語頻度をプロットすると、うまくいくようです。
しかし、最適な zipf 分布の計算に問題があります。結果は次のようになります。
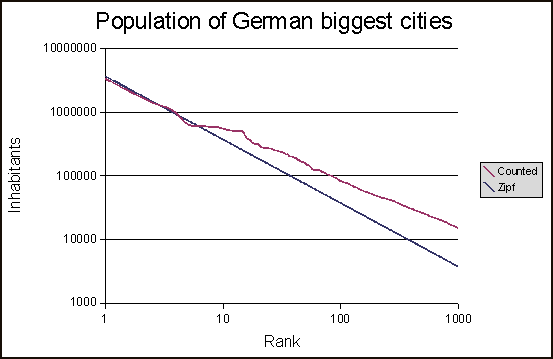
直線を計算するための式がどのようになるかわかりませんzipf。
zipf法律のドイツのウィキペディアのページで、うまくいくように見える方程式を見つけました

しかし、引用された情報源がないので、の定数がどこから来たのかわかりません1.78。
このスクリプトを使用した結果は次のようになります。

しかし、最適なzipf分布が正しく計算されているかどうかはわかりません。もしそうなら、最適なzipf分布は X 軸を 1 点で横切るべきではないでしょうか?
編集:それが役立つ場合、私のテキストには2440400のトークンと27491のタイプがあります