最大 1GB の XML ファイルがあります。OutOfMemory 例外を回避するために XOM を使用しています。
ドキュメント全体を正規化する必要がありますが、1.5 MB のファイルでも正規化に時間がかかります。
これが私がやったことです:
このサンプル XML ファイルがあり、Item ノードを複製してドキュメントのサイズを増やします。
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<Packet id="some" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<Head>
<PacketId>a34567890</PacketId>
<PacketHeadItem1>12345</PacketHeadItem1>
<PacketHeadItem2>1</PacketHeadItem2>
<PacketHeadItem3>18</PacketHeadItem3>
<PacketHeadItem4/>
<PacketHeadItem5>12082011111408</PacketHeadItem5>
<PacketHeadItem6>1</PacketHeadItem6>
</Head>
<List id="list">
<Item>
<Item1>item1</Item1>
<Item2>item2</Item2>
<Item3>item3</Item3>
<Item4>item4</Item4>
<Item5>item5</Item5>
<Item6>item6</Item6>
<Item7>item7</Item7>
</Item>
</List>
</Packet>
正規化に使用しているコードは次のとおりです。
private static void canonXOM() throws Exception {
String file = "D:\\PACKET.xml";
FileInputStream xmlFile = new FileInputStream(file);
Builder builder = new Builder(false);
Document doc = builder.build(xmlFile);
FileOutputStream fos = new FileOutputStream("D:\\canon.xml");
Canonicalizer outputter = new Canonicalizer(fos);
System.out.println("Query");
Nodes nodes = doc.getRootElement().query("./descendant-or-self::node()|./@*");
System.out.println("Canon");
outputter.write(nodes);
fos.close();
}
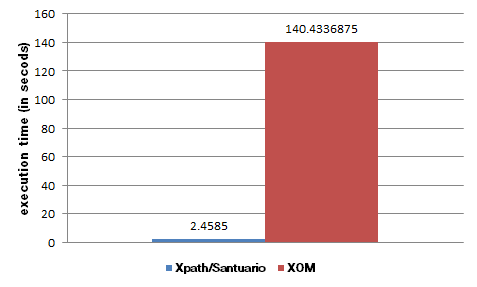
このコードは小さなファイルにはうまく機能しますが、私の開発環境 (4 GB RAM、64 ビット、Eclipse、Windows) では、1.5 MB のファイルの正規化部分に約 7 分かかります。
この遅延の原因へのポインタは高く評価されます。
PS。XML ドキュメント全体からのセグメントと、ドキュメント全体を正規化する必要があります。したがって、ドキュメント自体を引数として使用してもうまくいきません。
一番