問題タブ [bayesian-networks]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
artificial-intelligence - ベイジアン ネットワークの設計
ベイジアン ネットワークについての基本的な質問があります。
- 1/3 の確率で動かなくなるエンジンがあるとしましょう。この変数を ENGINE と呼びます。
- それが機能しなくなったら、あなたの車は機能しません。エンジンが作動していれば、あなたの車は 99% の確率で作動します。これを CAR と呼びます。
- さて、あなたの車が古い (OLD) 場合、1/3 の時間ではなく、1/2 の時間でエンジンが停止します。
最初にネットワークを設計してから、テーブルに関連付けられたすべての条件付き確率を割り当てるように求められています。
このネットワークの図は次のようになります
ここで、条件付き確率テーブルについて、次のことを行いました。
と
現在、OLD の確率を定義する方法に問題があります。古いというのは僕的にはENGINEと因果関係があるものではなく、どちらかというとその持ち味だと思います。これを図で表現する別の方法があるのではないでしょうか?図が本当に正しい場合、どのように表を作成しますか?
matrix - ベイジアン ネットワークの混同行列
ベイジアンネットワークを理解しようとしています。10 個の属性を持つデータ ファイルがあり、このデータ テーブルの混同テーブルを取得したいので、すべてのフィールドの tp、fp、fn、tn を計算する必要があると考えました。本当ですか?それなら、ベイジアンネットワークのために私がしなければならないことです。
本当にいくつかのガイダンスが必要です、私は迷っています。
bayesian - デシジョンツリーとベイジアンネットワークの違いは何ですか?
私が正しく理解していれば、どちらもベイズの定理を使用して非巡回グラフを生成し、すべてのノードに適用されている関数に基づいてパーセンテージを計算します。
違いはなんですか?
statistics - AI/色の名前を決定するための統計的手法
あらかじめ決められた候補のリストから、(RGB値)の色の名前を推測するための小さなライブラリを作成することを考えています。
私の最初の試みは、純粋に3次元RGB色空間内のピタゴリアン距離に基づいていました-名前の付いた色点のほとんどが空間の端にあったため(たとえば、0、0、255の青)、これは大した成功ではありませんでした。 、スペースの中央にあるほとんどの色では、最も近い名前の色もかなり恣意的でした。
だから、私はより良いアプローチを考えていて、いくつかの候補を考え出しました
HSV色空間内の円柱距離-上記と同様の問題が発生する可能性がありますが、HSVは、RGBよりも人間的な意味で意味があるように思われます。これは便利です。
上記のいずれかですが、名前が付けられた各カラーポイントは、周囲の空間内のポイントへの引力の強さを示す任意の値で重み付けされています。そのようなモデルの名前はありますか?これは少し漠然としていると思いますが、私にはかなり直感的なアイデアのようです。
HSV色のプロパティを調べて、最も可能性の高い色名を返すベイジアンネットワーク(たとえば、P(黒|彩度<10)、P(赤|色相= 0)に似たノードを想像していますが、これは理想的とは言えません-たとえば、特定の色が赤になる確率は、離散値ではなく、色相が0にどれだけ近いかに比例します。ベイジアンネットワークを適応させて、テストされている変数?
最後に、HSVまたはRGB色空間内のサポートベクターマシンベースの分類があるかどうか疑問に思っていましたが、これらにあまり精通していないため、これがピタゴラス距離ベースのアプローチよりも特別な利点を提供するかどうかはわかりません。特に私は3次元空間しか扱っていないので、最初に試しました。
したがって、私は疑問に思っていました、あなたの誰かが同様の問題の経験を持っているか、または私がアプローチを決定するのを助けることができるかもしれないリソースを知っていますか?誰かが私を正しい方向に向けることができれば(それが上記のいずれかであろうと、まったく異なるものであろうと)、私は非常に感謝しています。
乾杯!
ティム
neural-network - 人工ニューラルネットワークとベイジアンネットワークの違い
私はインターンシップ プロジェクトに取り組んでいる学生です。そこでは、ベイジアン ネットワークを使用して、特定の一連の離散親変数から可能な結果を予測しています。現在、人工ニューラル ネットワークを使用してタスクを実行するつもりです。誰か助けてください。ベイジアン ネットワークと人工ニューラル ネットワークの類似点と相違点について教えてください。移行を進める方法についての提案は役に立ちます。
ありがとう
c++ - iPhone用のベイジアンネットワークライブラリ?
iphone で動作するベイジアン ネットワーク ライブラリを探しています。ヒントはありますか?
python - 特定のアプリケーション向けのベイジアン ネットワークの Pythonic 実装
これが、私がこの質問をしている理由です。 昨年、特定のタイプのモデル (ベイジアン ネットワークで記述) の事後確率を計算する C++ コードをいくつか作成しました。このモデルはうまく機能し、他の人が私のソフトウェアを使い始めました。今、私は自分のモデルを改善したいと考えています。私はすでに新しいモデル用にわずかに異なる推論アルゴリズムをコーディングしているので、ランタイムはそれほど重要ではなく、Python を使用するとよりエレガントで扱いやすいコードを作成できる可能性があるため、Python を使用することにしました。
通常、このような状況では、Python で既存のベイジアン ネットワーク パッケージを検索しますが、使用している推論アルゴリズムは独自のものであり、Python の優れた設計についてさらに学ぶ絶好の機会になると考えました。
ネットワーク グラフ用の優れた Python モジュール (networkx) を既に見つけました。これにより、各ノードと各エッジに辞書をアタッチできます。基本的に、これにより、ノードとエッジのプロパティを指定できます。
特定のネットワークとその観測データについて、モデル内の割り当てられていない変数の可能性を計算する関数を作成する必要があります。
たとえば、従来の「アジア」ネットワーク ( http://www.bayesserver.com/Resources/Images/AsiaNetwork.png ) では、「XRay Result」と「Dyspnea」の状態がわかっているため、関数を記述する必要があります。他の変数が特定の値を持つ可能性を計算します (モデルに従って)。
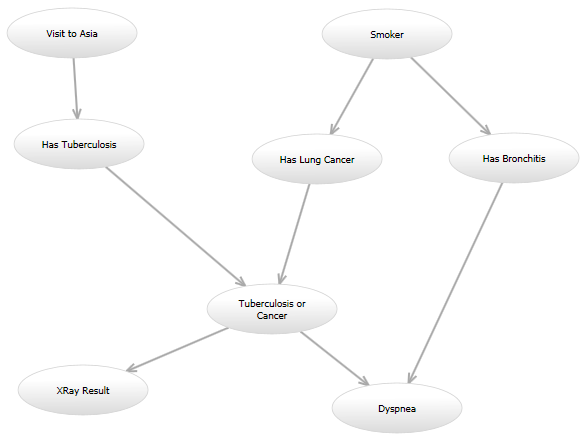{kind=link}
これが私のプログラミングに関する質問です。 いくつかのモデルを試してみるつもりですが、将来的には別のモデルを試してみたいと思うかもしれません。たとえば、1 つのモデルがアジア ネットワークとまったく同じように見える場合があります。別のモデルでは、「Visit to Asia」から「Has Lung Cancer」に有向エッジが追加される場合があります。別のモデルは元の有向グラフを使用する場合がありますが、「結核または癌」ノードと「気管支炎あり」ノードが与えられた場合、「呼吸困難」ノードの確率モデルは異なる場合があります。これらのモデルはすべて、異なる方法で尤度を計算します。
すべてのモデルにはかなりの重複があります。たとえば、「Or」ノードに入る複数のエッジは、すべての入力が「0」の場合は常に「0」になり、それ以外の場合は「1」になります。ただし、モデルによっては、ある範囲の整数値を取るノードを持つものもあれば、ブール型のものもあります。
過去に、私はこのようなことをプログラムする方法に苦労しました。うそをつくつもりはありません。かなりの量のコードをコピーして貼り付けており、1 つのメソッドの変更を複数のファイルに反映する必要がある場合がありました。今回は、これを正しい方法で行うために時間を費やしたいと思っています。
いくつかのオプション:
- 私はすでにこれを正しい方法で行っていました。最初にコーディングし、後で質問します。コードをコピーして貼り付け、モデルごとに 1 つのクラスを作成する方が高速です。世界は暗く無秩序な場所です...
- 各モデルは独自のクラスですが、一般的な BayesianNetwork モデルのサブクラスでもあります。この一般的なモデルは、オーバーライドされるいくつかの関数を使用します。Stroustrup は誇りに思うでしょう。
- 異なる尤度を計算する同じクラスにいくつかの関数を作成します。
- 一般的な BayesianNetwork ライブラリをコーディングし、このライブラリによって読み取られる特定のグラフとして推論の問題を実装します。ノードとエッジには、"Boolean" や "OrFunction" などのプロパティを指定する必要があります。これらは、親ノードの既知の状態を考慮して、さまざまな結果の確率を計算するために使用できます。これらのプロパティ文字列 ("OrFunction" など) を使用して、適切な関数を検索して呼び出すこともできます。おそらく数年後には、1988 年版の Mathematica に似たものを作ることになるでしょう!
どうもありがとうございました。
更新: ここではオブジェクト指向のアイデアが大いに役立ちます (各ノードには、特定のノード サブタイプの先行ノードの指定されたセットがあり、各ノードには、先行ノードの状態などを考慮して、さまざまな結果状態の可能性を計算する尤度関数があります。 )。おっと!
algorithm - 無向グラフを三角測量するための汎用アルゴリズム?
ベイジアンネットワークでの信念伝播のためのジャンクションツリーアルゴリズムの実装をいじっています。ジャンクション ツリーを形成できるように、グラフを三角測量するのに少し苦労しています。
最適な三角形分割を見つけることが NP 完全であることは理解していますが、比較的単純なベイジアン ネットワークに対して「十分な」三角形分割をもたらす汎用アルゴリズムを教えていただけますか?
これは学習課題 (趣味であり、宿題ではありません) であるため、無向グラフが与えられた場合にアルゴリズムが三角グラフになる限り、空間/時間の複雑さはあまり気にしません。最終的には、何らかの近似を試みる前に、正確な推論アルゴリズムがどのように機能するかを理解しようとしています。
私は NetworkX を使用して Python をいじっていますが、典型的なグラフ トラバーサルの用語を使用したそのようなアルゴリズムの疑似コードの記述は価値があります。
ありがとう!
java - Bayesian Belief Network Framework "Infer.NET" に代わる Java はありますか?
Bayesian Belief Network フレームワーク - Infer.NET の Java 代替品はありますか? スケーラブル (大規模なデータセットのオンライン学習)、十分にサポートされている (最終更新は 2010 年以降)、オープン ソースであり、ネットワーク構造を簡単に記述できる場合に適しています。つまり、Infer.NET のすべての機能です。
combinatorics - ベイジアン ネットワークを周縁化するためのステップ数の計算
小さなベイジアン ネットワーク (DAG で表される) でノードを削除するための最も効率的な順序を見つけるアルゴリズムを作成しようとしています。すべてのノードはブール値であり、2 つの可能な状態を取ることができます。
私の最初の計画は、先行変数が残っていない残りの変数を再帰的に選択し、その可能な状態ごとに、グラフを介して値を伝播することでした。これにより、考えられるすべてのトポロジー順序が得られます。
位相的な順序付けを考慮して、疎外することのコストを見つけたいと思いました。
たとえば、このグラフ:
U --> V --> W --> X --> Y --> Z
にはそのような順序 (U、V、W、X、Y、Z) が 1 つだけあります。
結合密度を因数分解できます g(U,V,W,X,Y,Z) = f1(U) f2(V,U) f3(W,V) f4(X,W) f5(Y,X) f6 (Z,Y)
したがって、この順序付けに対応する周縁化は次のようになります。
∑(∑(∑(∑(∑(∑(g(W,X,Y,Z),Z),Y),X),W),V),U) =
∑(∑(∑(∑(∑∑) (∑(f1(U) f2(V,U) f3(W,V) f4(X,W) f5(Y,X) f6(Z,Y),Z),Y),X),W), V),U) =
∑(f1(U)
∑(f2(V,U)
∑(f3(W,V)
∑(f4(X,W))
∑(f5(Y,X)
∑(f6(Z, Y)、Z)
、Y)
、X)
、W)
、V)
、U)
このグラフの場合U --> V、4 ステップで V のシンボリック関数に変換できます (すべての U xすべての V。それを考えると、V --> W同様に 4 ステップでシンボリック関数に変換できます。したがって、全体で 18 ステップ (4+4) かかります。 +4+4+2 (Z には状態が 1 つしかないため)。
これが私の質問です。この順序でこの合計を計算できる最速のステップ数を決定するにはどうすればよいですか?
助けてくれてどうもありがとう!