問題タブ [natural-logarithm]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
python - Python の ln (自然対数)
この課題では、この問題を除くすべての問題を完了しました。方程式を解くために Python スクリプトを作成する必要があります (スクリーンショット)。
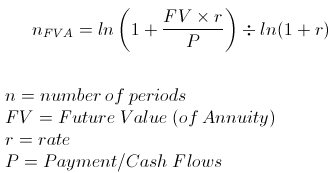
残念ながら、インターネット全体での私の調査では、ln をログに変換する方法や、使用可能なものなど、世界でどのように変換するかを理解できません。これまでに書いたコードは以下のとおりです。私たちの先生が私たちが得るべきだと言っている答えも投稿します。
私が得るべき答えは 36.55539635919235 です。
また、numpy は使用していません。私はすでにそれを試みました。
ありがとう!
math - 対数を 8.8 固定小数点に変換するための適切な倍率を探しています
私は数字の範囲を持っています(0, 1]
これらの数値の自然対数を取り、8.8 固定小数点として保存したいと思います。
私のフォーラムは K*ln(x) + (1<<16)
しかし、私は最高の価値が何であるか分かりませんK 。
私の考えでは、x2倍になるとln(x)が増加するln(2)ため、固定小数点の値は固定小数点で1増加する必要があります(つまり、256)
つまり、これは次のことを意味します。K = 256/ln(2)
これは理にかなっていますか?
ggplot2 - Rとggplot2:軸を対数スケールに変換する方法は? 与えられた信頼区間の制約
私はここにいるのは初めてで、本当に助けていただければ幸いです!ggplot を使用して対数変換されたデータをプロットし、95% の信頼区間と予測区間をプロットする単純な r スクリプトがあります。ただし、軸をフォーマットする方法にこだわっています...対数スケールにしたいです。私はチュートリアルからこれを学び、スクリプトを実行してから軸を変換しようとしましたが、信頼区間が台無しになります。
私は使用してみました:
しかし、それは95%の信頼区間を変換しません...どんな提案もいただければ幸いです! 基本的に、私は、すでに素晴らしいグラフで見栄えのする対数スケールを取得する簡単な方法を探しています。
これが私のコードです(参照用にすべてのデータを少しだけ含めたわけではありません):
r - b/wa カテゴリカル DV と連続 IV の関係のプロット
私は最近、カテゴリ結果変数 (0 = 不規則動詞生成、1 = 通常動詞生成) が連続変数 (既存の動詞との音韻類似性) によって有意に予測されることを示す論文を提出しました。具体的には、glmer モデルは、類似性尺度が増加すると、通常の動詞の生成が大幅に可能性が高いことを示しました。
Y 軸に MEAN 生産をプロットし、x 軸に類似度をプロットして、この関係をプロットしました。しかし、レビュアーは、「対数オッズスケールで軸をプロットする」ことをかなり漠然と尋ねました. ここで何を意味するのかを正確に理解するのに苦労しています.これが、カテゴリ結果変数と連続変数の間の関係をプロットするための標準要件であるかどうか疑問に思っています?
x 軸と y 軸の両方を対数変換してから同じプロットを作成するのと同じくらい簡単ですか (つまり、x 軸 = 自然対数変換された平均生産; y 軸 = 自然対数変換された類似度)? こうすると、変形していないものとプロットが同じに見えるので、何か別のものを試した方がいいのでしょうか?
助けてくれてありがとう。ライアン
python - ln関数をプロットするMatplotlib
わかりました。これが可能かどうかはわかりません。xとyの両方の自然対数関数を持つmatplotlibを使用して、Pythonでグラフをプロットしようとしています。
まず、自然対数を使用してプロットする方法に関する指示を含む投稿を探しました。ここで答えの一部を見つけ、他の部分をここで見つけました。
問題は、2 つの線を 1 つのグラフにプロットしようとしていることです。
方程式は次のとおりです。
1) 0.91 - 0.42 * P = Q
2) 6.999 - .7903 * ln (P) = ln (Q)
スケールの問題を考えると、これらの 2 つの線を 1 つのグラフに重ねることは可能ですか? どうすればいいですか?
私は次のことを試しました:
しかし、これはエラーを返します:
ValueError: posx と posy は有限値でなければなりません