問題タブ [syntaxnet]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
corpus - Syntaxnet を使用してコーパスに注釈を付ける
Syntaxnet を使用してコーパスに注釈を付けようとしています。/models/syntaxnet/syntaxnet/models/parsey_mcparseface/context.pbtxt ファイルの末尾に次の行を追加しました。
コマンドを実行すると:
私は得ています:
## here ## の回答によると、demo.sh ファイルを変更したところ、次のようなエラーが表示されました。
可能な解決策は何ですか?
python - SyntaxNet の「評価メトリック」とは何を意味しますか?
私はSyntaxNetで遊んでいます。各実行の後、次のような行が出力されます。
parser_eval.py の 134 行目までたどりました。
精度の尺度のようですが、どのように計算され、何を意味するのでしょうか?
parsing - 注釈を理解する - Syntaxnet
1400 件のツイートのセットに対して、Syntaxnet を正常に構築して実行しました。解析されたファイルの各パラメータが何を意味するのか理解できません。たとえば、次の文があります。
解析されたファイルの内容は次のとおりです。
各列の正確な意味は何ですか? POS タグ以外に空白や数字があるのはなぜですか?
tensorflow - シンタックスネット モデル (Parsey McParseface) をエクスポートして、TensorFlow Serving で提供することはできますか?
私は demo.sh が正常に動作していて、parser_eval.py を見て、ある程度理解しました。ただし、TensorFlow Serving を使用してこのモデルを提供する方法がわかりません。上から見ることができる2つの問題があります。
1) これらのグラフにはエクスポートされたモデルはありません。グラフは、呼び出しごとにグラフ ビルダー (たとえば、structured_graph_builder.py)、コンテキスト プロトコル バッファー、および現時点では完全に理解していないその他のものを使用して構築されます。 (追加の syntaxnet.ops も登録しているようです)。SessionBundleFactoryそれで...それは可能ですか?また、これらのモデルをServingと. そうでない場合は、サービングが C++ コンテキストでのみ実行されるため、グラフ構築ロジック / ステップを C++ で再実装する必要があるようです。
2) demo.sh は、実際には UNIX パイプで文字通りパイプ接続された 2 つのモデルであるため、Servable は (おそらく) 2 つのセッションを構築し、一方から他方へデータをマーシャリングする必要があります。これは正しいアプローチですか?または、両方のモデルを一緒に「パッチ」して含む「大きな」グラフを作成し、代わりにそれをエクスポートすることは可能ですか?
python - SyntaxNet 出力を使用して実行コマンドを操作する方法 (たとえば、Linux システムでファイルをフォルダーに保存する)
SyntaxNetをダウンロードしてトレーニングした後、AutoCAD ファイルなどの新規/既存のファイルを開き、テキストを分析してファイルを特定のディレクトリに保存できるプログラムを作成しようとしています: open LibreOffice file X。SyntaxNet の出力を次のように考えます。
最初に、解析されたテキストを XML 形式に変更することを考えました。次に、XML ファイルをセマンティック分析 ( などSPARQL) で解析して、ROOT=save、dobj=X、および nummode=Y を見つけ、言われているのと同じことを実行できる python プログラムを作成します。本文中
ROOT解析されたテキストを XML に変更し、クエリを使用するセマンティック分析を使用して、対応する関数またはスクリプトを保存するスクリプトとdobj一致させるかどうかはわかりません 。nummodeパッケージを使用してpythonを端末に接続するアイデアがいくつかあり
subprocessますが、たとえばAUTOCADファイルやその他のファイルを端末から保存するのに役立つものは見つかりませんでし.shた。パイソンの助け?
Christian Chiarcos (2011 ) 、Hunter and Cohen (2006 ) 、Verspoor et al. (2015 )などのテキストの構文および意味分析について膨大な調査を行い、Microsoft Cortana、Sirius、Google も現在研究していますが、いずれも彼らが解析されたテキストを実行コマンドに変更する方法の詳細を見て、この作業について話すのは簡単すぎるという結論に達しましたが、私はコンピュータ サイエンスの専門家ではないので、それについて何ができるかわかりません。
python - SyntexNet Parsey McParseface を使用したトレーニング コーパスの作成
私は現在、Tensorflow を学習しようとしていますが、いくつかのコーパスのデータセットを作成する必要があるところまで来ています。LDC の注釈付き Gigaword 英語コーパスに投じるお金がないので、独自のスクレーパーを作成することを考えています。オンラインからいくつかの記事を入手しましたが、ここで LDC Gigaword サンプルと同様の方法でフォーマットしたいと思います: https://catalog.ldc.upenn.edu/desc/addenda/LDC2012T21.jpg
{kind=link}
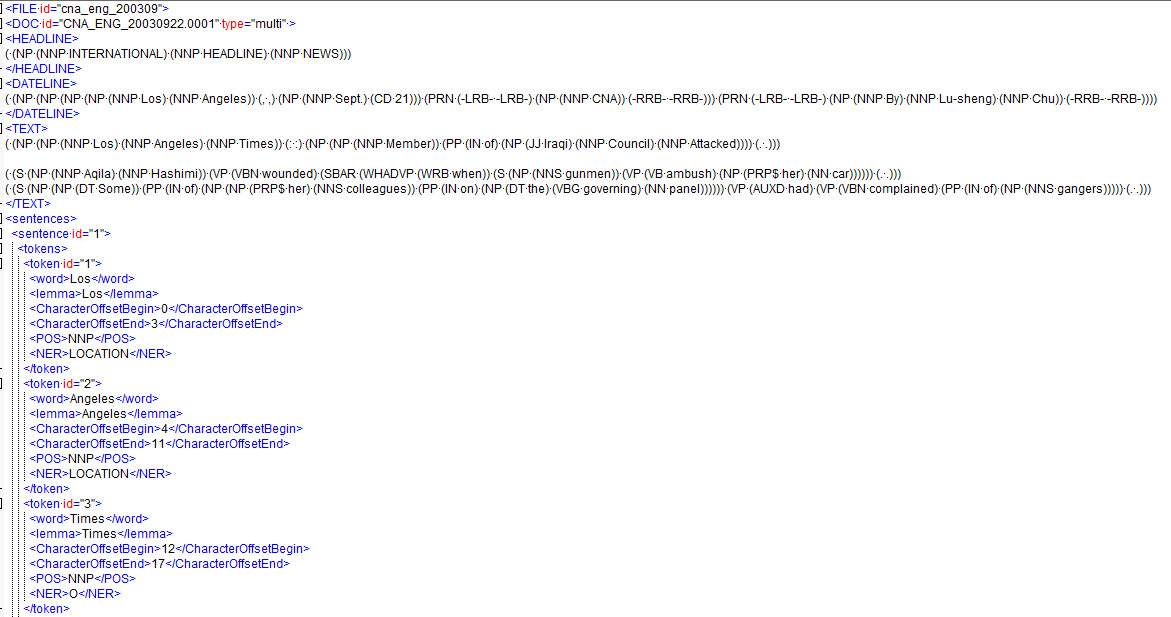
Parsey Mcparseface モデルを使用して、入力に POS タグを付け、複数の xml ファイルを出力しようとしています。私は現在、pythonを使用してconll2tree.pyファイルとdemo.shファイルを変更して、単一のファイルから入力を読み取れるようにすることで、必要な出力に近づきました。使用したコマンドラインは、この投稿の下部に示されています。
私が理解しようとしているのは、モデルがディレクトリ内のすべてのファイルを処理する方法です。私の現在のスクレーパーは JavaScript で書かれており、タイトル、本文、画像などの json オブジェクトを含む個別の .json ファイルを出力します。文の境界検出を使用して各文をコンマで区切りましたが、解析への入力が必要になるようです各文が異なる行にある入力になります。これを Python スクリプトで変更しますが、各ファイルを反復処理し、コンテンツを読み込んで処理し、次のファイルに移動できるように、以下のパラメーターを構成する方法についてはまだわかりません。入力パラメータにワイルドカードを設定する方法はありますか? または、Python スクリプトでコマンドライン経由で各ファイルを個別に送信する必要がありますか? パーシーモデルまたはSyntexNetがそれらをバッチで処理できる方法があるかどうかを推測します。
私が持っていたもう1つの質問は、上の画像の「見出し」に示されているような形式をParsey Mcparsefaceに出力させる方法があるかどうかです。
(.(NP.(NNP.INTERNATIONAL).(NNP.HEADLINE).(NNP.NEWS)))
そうでない場合、この形式は何と呼ばれているので、コードを介して自分でこれを行う方法を詳しく調べることができますか? 私をうんざりさせている部分は、NPのプレフィックス番号です(名詞句を想定)。
文のトークンを介して示されている画像のような形式に POS タグを抽出することができましたが、Tensorflow を深く理解するにつれて、それらが表示されている形式にするのが良いと思います。単語同士の関係をより多く示すため、headline タグと textfield タグも同様です。
また、次のエントリを content.pbtxt ファイルに追加しました。
python - Python asciitree 出力の解析と「ラベル付きブラケット表記」の出力
Google SyntaxNet は .. のような出力を提供します。
Python を使用して、この出力 (文字列データ) を読み取って解析したいと考えています。->のように「ラベル付きブラケット表記」で出力します
手伝って頂けますか?
tensorflow - bazel が使用する CPU コアの数を指定するにはどうすればよいですか?
私はbazelでシンタックスネット(テンソルフローフォーク)を構築しています。動作が非常に遅く、ハングアップし続けます。
前回 (caffe で) この問題が発生したとき、使用しているコアの数を追加して変更するように誰かに言われました-j4。bazel では、このコマンドは機能しませんでした。このような bazel のカスタム コマンドはありますか?
CPU スペック: 3.8GHz クロック、クアッドコア
CPU モデル: AMD 4800 (またはそれに沿ったもの)。
tensorflow - tensorflow tensorflow-serving と syntaxnet から bazel アーティファクトを組み合わせる方法は?
私はbazelを使用してsyntaxnetとtensorflow-servingを構築しました。どちらも tensorflow 自体の独自の (部分的な?) コピーを埋め込みます。私はすでに、理解できないシンタックスネットツリーに「住んでいる」スクリプトでテンソルフローサービスの一部を「インポート」したいという問題を抱えています(いくつかの非常に醜いことをしなければ)。
今、私は「テンソルボード」が欲しいのですが、それはどうやらsyntaxnetまたはtensorflow-servingの中に埋め込まれたtensorflowの一部として構築されません。
だから、「自分のやり方が間違っている」と確信しています。さまざまな個別の bazel ワークスペースによって構築されたアーティファクトをどのように組み合わせる必要がありますか?
特に、tensorflow (tensorboard を使用) AND syntaxnet AND tensorflow-serving を構築し、それらを使用するために「インストール」して、完全に別のディレクトリ/リポジトリに独自のスクリプトを書き始めることができるようにするにはどうすればよいですか?
「./bazel-bin/blah」は本当に bazel のエンド ゲームですか? 「make install」に相当するものはありませんか?