問題タブ [weighted]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
javascript - JavaScript 加重ランダムまたは時間の割合
100 ミリ秒ごとに実行される Node.js プロセス (setInterval) があります。x期間ごとに実行したい特定のアクションがあります。たとえば、2% の確率で X を実行し、10% の確率で Y を実行します。
現在、私は基本的に次のようにしています。
問題は、非常に一貫性がないことです。if(rand > 900)少なくとも 10% の確率で実行する必要がありますが、連続して 10 倍になるか、まったく実行されない場合もあります。
100ミリ秒の間隔が固定されていると仮定した場合、より正確な解決策を提案してくれる人はいますか?
ありがとうございました!
編集: ドレデル博士のコメントに基づく:
line - 最適な線を見つけるための加重最小二乗法
いくつかのデータポイント(x、y)に最適な線を見つけようとしています。ここで説明されている最小二乗法を使用していますhttp://faculty.cs.niu.edu/~hutchins/csci230/best-fit.htm
ただし、各データポイントに重みを追加できるようにアルゴリズムを調整する必要があります。そうすると、データセット内の他のポイントよりも重要なポイントに対して線がより傾斜します。
私は非常に基本的な統計しか知らないことに注意してください。答えるときは、基本的な知識を持った人に説明していることに注意してください。
javascript - 配列からの加重平均
次の加重平均式を JavaScript で記述する必要があります。
平均 = (p1*p2*x1 + p3*p4*x2 + ... +p(n-2)*p(n-1)*xn) / (p1*p2 + p3*p4 + ... + p (n-2)p(n-1) )
式は、x値の平均を示します。
また、 arrayJavaScriptのn要素が取り込まれています。
...平均を求めるpi重みと値はどこにありますか。xi
この配列を使用して数式を作成するにはどうすればよいですか?
django - Django 多基準加重評価
複数基準の加重評価を必要とするアプリを Django で作成し始めました。私の問題は、数年前のこの問題とまったく同じですが、残念ながら答えがありませんでした.
Django で多基準加重評価を作成する方法についてヒントをくれる人がいたら、ぜひ教えてください! 私は Django/Python の世界全体にかなり慣れておらず、PHP のバックグラウンドを持っています。
どうもありがとう!
PS: このスレッドにはあまり情報を入れませんでした。この問題は、こちらの別のトピックで既に説明されているためです。それはまったく同じことです。
java - 負のサイクルを利用して、グラフ上の 2 つのノード間のゼロ/負の重みのパスを見つける
タイトルでこれを説明するのに本当に苦労しましたが、長い形式で試してみます。
私はこの問題に本当に困惑しており、答えを探しているのではなく、ちょっとした助けや読むべき特定のトピックを探しています.
私が持っているのは、負と正の両方のさまざまな重みのエッジを持つ有向グラフです。私がやろうとしているのは、グラフ上に配置された 2 つのノードを備えた (そしてそれらが接続されていると仮定して) アルゴリズムを作成し、それらの間のパスを見つけて、パスの合計重みがゼロまたは負になるようにすることです。パスには複数回ノードを含めることができます (うまくいけば、含まれるエッジの正の重みをパスが相殺できるようになります)。
私は現在、ラッセルとノーヴィグの人工知能を読んでいますが、さまざまな問題があるため、テキストのロジックを自分の問題に適用する方法を見つけるのに苦労しています (アルゴリズムは常に負のサイクルを回っています)。このために Backtrack や AStar などのメソッドを利用する方法を完全には理解していません
誰かが私の問題をよりよく理解するのに役立つ何かの正しい方向に私を向けることができれば、それは大きな助けになります.DFSとBFS、およびグラフに関連する他の多くのことをうまく処理できますが、パスを見つける必要があります.重量制限のある2つのノード間は本当に困惑しています。
ありがとう
以下にサンプル グラフを示します。パスの合計重みがゼロを超えない、開始からゴールまでのパスを見つける必要があります。
グラフの例 http://i144.photobucket.com/albums/r166/ZooropaTV/bu.jpg
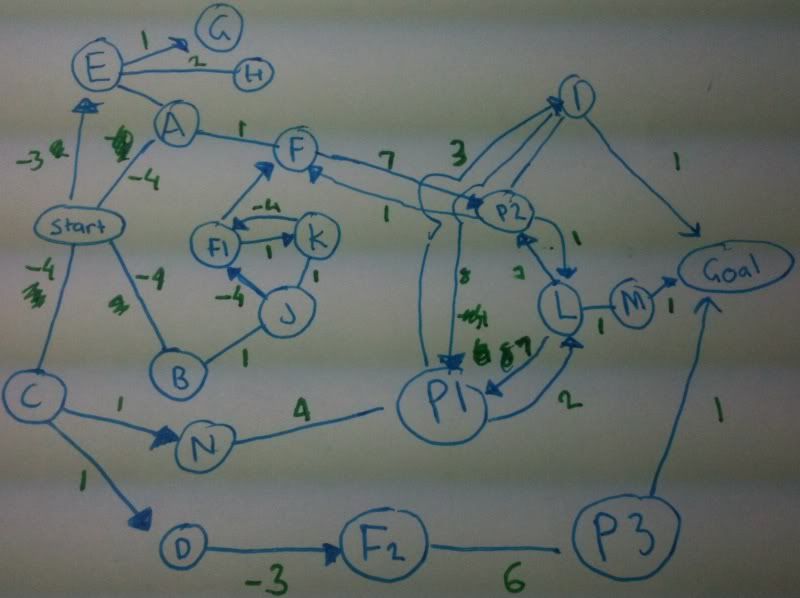{kind=link}
私の目標は必ずしも重量で最短経路を見つけることではないので、私が行ってきた検索/読み取りの多くが見当違いであることに気付きましたが、必要最小限のノード数にアクセスすることで、別のことを考える必要があります今更ですが、何かアドバイスがあればお願いします
algorithm - 順序を維持しながら、2 つの順序付けられたリスト内のアイテムの最適なペアリング戦略のアルゴリズム
次の 2 つの順序付きリストがあります。
各アイテムには、文字列の長さに等しいスコアがあるので...
各リストに表示される順序を変更せずに、ペアの A からのインデックスまたは B からのインデックス、またはその両方を含むペア (A,B) のリストを作成したいと考えています。
次に、各ペアにはそのアイテムのスコアがあるため、アイテムをペアにすることで、両方のアイテムの合計スコアが半分になります。最小スコアを持つペアの組み合わせを取得したい。
たとえば、上記の 2 つのリストでは、各アイテムをペアにすることができますが、リストの 1 つの順序を変更せずに両方をペアにすることはできないため、一部のペアでは他のアイテムをペアにすることができません。たとえば、一方のリストでは前に、もう一方のリストでは後"blueberries"にペアリングすることはできません。どちらか一方しかペアリングできませんでした。各リストには、同じアイテムが複数回含まれている場合もあります。"oranges""oranges" "blueberries"
上記の問題の最適な結果は...
答えは次のようなものだと思います。
- ペアを見つける
- それらのペアを可能なペアのグループに分割します
- 最大の重みを持つグループを計算します
ペアをあるリストから別のリストに結合することにより、どのペアが他のどのペアを除外するかを視覚的に判断できます。その結合が別の結合と交差する場合は、それを除外します。ただし、これがプログラムでどのように行われるかはわかりません。
どうすればこの問題を解決できますか?
algorithm - リスト項目を徐々にバブリングしながら加重シャッフルを実行するアルゴリズム
リスト内の各項目が同時にリストの一番上に向かって機能するように、重みバイアスを許可するリストのシャッフルを実行するための単純なアルゴリズムを誰かが知っているかどうか疑問に思っています。
ページ分割されたディレクトリにビジネス リスティングがあるサイトで作業しています。リスティングを公平に表示する必要があるため、あるビジネスが常に別のリスティングの上/下にあるとは限りません。ディレクトリの純粋なシャッフルは実際には十分ではありません。これのランダムな性質により、特定のビジネスがリスト内の同様の場所に長期間にわたってランダムにシャッフルされる可能性があるためです。リストはゆっくりとリストを上に移動し、時間の経過とともにディレクトリの最初のページに表示される機会が合理的に均等になるようにします。
編集:
Kevin からの感謝を込めて - 私はこれらのルールを形式化しようとしています:
1) n 個のリストの場合、各リストは n 回の「準シャッフル」で 1 番目の位置に表示する必要があります)
2) (あいまい) リストの平均 (?) 順位は、順位 1 に達するまで時間の経過とともに増加するはずです。
3) 任意の 2 つのビジネス (A と B) について、n 回のシャッフルの繰り返しで、A が 50% を超えて B を上回ってはなりませんか?
また、私は非常に複雑で入り組んだ「シャッフラー」を持つビジネスで働いていることも付け加えておく必要があります。これは、ディレクトリ内のビジネスのそれぞれのカテゴリに公平に分散することを主張する多数の有料クライアントをなだめるために必要です。顧客からの苦情は「本当の」問題です。ユーザーは通常、ページ分割されたページの最初の数ページからアイテムを選択するため、クライアントをアルファベット順 (デフォルト) で注文するのは公平ではなく、ユーザーが上から下に読むことを考えると、そうではありません。あるビジネスが常に他のビジネスよりも優れていることを公正に示します。
以前に実装した可能性のある、この問題に対する適切な解決策を誰かが持っているかどうかを知りたいです。
編集:
これらのアイテムがデータベースに保存されていることを考えると、アイテムが最初の位置に達したときに、順序付け (降順) に使用できる、時間の経過に伴う各リストの位置の合計である列を作成できます。リストを 0 に設定すると、リスト内のすべての項目が最終的にリストの一番上に表示されます。問題は、多数のリストの場合、時間の経過とともに、この数がかなり大きくなる可能性があることです...
編集:
データベースをバタンと閉めたくないので、ユーザーがブラウジングしている間は一貫性が必要なので、ディレクトリのすべての表示ではなく、毎晩(1日1回)「疑似シャッフル」を実行するだけです
average - 各セットの個々の加重スコアを計算する方法は?
私は 20 問あり、それらはさらにそれぞれ 4 つの問題のセットに分割されています。つまり、合計 5 つのセット A、B、C、D、E があることを意味します。得られるのは20です。
各セットに対して行われた2つのテストで、次の結果が得られました
今私が望むのは、C と D のセットを他のすべてのセットのほぼ 2 倍に重み付けしたいということです。加重パーセンテージを計算するには、次のようにします。
ここで、各セットの加重パーセンテージを個別に計算したいと思います。例えば、以前はそれぞれ 100% と 80% でしたが、重みが考慮されていなかったと仮定すると、(テスト 1 の) セット A とセット C の新しい重み付けパーセントは何パーセントになりますか。テスト 1 とテスト 2 の加重平均がそれぞれ 66.2% と 89.64% になるすべての個々のパーセンテージについても同様です。
次のようなロジックを入れようとしましたが、正確にはわかりません。これで私を助けてもらえますか?
とにかく、これはまったく可能ですか?
c - 加重ランダム整数
以下に示す重みを使用して、ランダムに生成された数値に重みを割り当てたいと思います。
それを行う最も効率的な方法は何ですか?
algorithm - [低、高]値ペアのセットに対する加重ランダム
{ キーワード: [低、高]、キーワード 1: [低 1、高 1]、キーワード 2: [低 2、高 2] ... } のリストがあり、キーワードを選択するために加重ランダム アルゴリズムを実行したいと考えています。すべてのリクエスト。とにかく、単純なアルゴリズムは結果をゆがめますか?
ありがとう、ラジャ。