問題タブ [omap]
For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Note JavaScript is NOT the same as Java! Please include all relevant tags on your question; e.g., [node.js], [jquery], [json], [reactjs], [angular], [ember.js], [vue.js], [typescript], [svelte], etc.
embedded - 水晶コア MPU クロックレートの違い
起動時に以下のように表示される組み込みシステムがあります。
クロッキングレート (クリスタル/コア/MPU): 12.0/400/1000 MHz
これら 3 つのクロック レートの違いについて説明してくれる人はいますか。プロセッサは ARMv7、OMAP3xxx
c++ - PowerVR を使用する Omap4 用の開発 EGL アプリ
私は Pandaboard を持っていて、OMAP4 で PowerVR をサポートしており、Imagination Examples をうまく試しました。しかし、自分のコードと開発アプリを自分のホスト マシンの Pandaboard または Omap4 に書き込む方法を考えていたので、クロス コンパイルですか?
ソリューションは PowerVR SDK ですか? それで、どのように?
注: Ubuntu 11.10 は Pandaboard (armhf) で実行されます。HostMachine(x86)で実行されるUbuntu 12.04
arm - OMAP 4460で複数のDMA転送が進行している間、CPUはブロックされていますか?
PandaboardでDMAがどのように機能するかを正確に知りたいです。Pandaboardで使用されているOMPA4460のTRMを読みました。これは、DMAシステムが一度に合計128の要求、最大32の論理チャネル、および4つの割り込み要求を管理できることを示しています。DMAの進行中に、CPUが一度に別のタスクを実行できる可能性はありますか?
arm - ARM Cortex-A9 で作られた SoC の典型的な L1 および L2 アクセス レイテンシ
複数の ARM A9 プロセッサを搭載した Nvidia Tegra 2 や Tegra 3 などの ARM Cortex-A9 プロセッサから作成された SoC の L1 アクセス レイテンシと L2 アクセス レイテンシを探しています。
これらのアーキテクチャの L1 と L2 のサイズに関する情報はいくつか見つかりましたが、L1 と L2 のアクセス遅延に関する情報はあまり見つかりませんでした。私が見つけた唯一の信頼できる情報は、「L2 キャッシュのレイテンシーは、Tegra 3 では 2 サイクルよりも 2 サイクル高速ですが、L1 キャッシュのレイテンシーは変わっていません」というものです。
Tegra 2 の L2 のレイテンシは 25 サイクルであり、L1 のレイテンシは 4 サイクル、L2 のレイテンシは 31 ~ 55 サイクルであることが示されています。これらの参照はどれも完全に信頼できるものではありません。Nvidia、TI、および Qualcomm の Web サイトと技術文書で詳細情報を見つけたいと思っていましたが、うまくいきませんでした。
編集: OMAP4460 や OMAP4470 などの同様の SoC に関する情報も役立ちます。
linux-kernel - カーネル oops oops: ARM 組み込みシステムで 80000005
このおっとを解決するのを手伝ってください。1ミリ秒の高解像度タイマーを使用し、「insmod」を使用して別のモジュールとしてインストールします。これは1ミリ秒ごとに発生し、このタイマー割り込みで何らかのタスクを実行する必要があります。画像転送を行う他のプロセスがあり、画像を送信するためにイーサネットドライバーが割り込みを行っているように見えます。この enet 割り込みは優先度が高く、上記の 1 ミリ秒のタイマー割り込みを遅らせているように見えますが、よくわかりません。
テストを 3 ~ 3 時間実行すると、次のエラーが表示されます。これを根本的に引き起こす方法は?助けてください。システムは ARM omap で、Linux 2.6.33 をクロス コンパイルして実行しています。
=========================================
========================
上記のコードをドライバーモジュールとして使用し、insmod で挿入します。これは 1 ミリ秒ごとに発生すると予想され、正常に動作しますが、ehernet トラフィックが多すぎると、説明したようにカーネルに Oops が発生することがあります。コードに問題があるかどうかを確認してください。
lsmod を確認したところ、5 つのカーネル モジュール (私自身のもの) がすべて 0x7f000000 から 0x7f02xxxx の間にロードされていることがわかりました。
oops アドレス 0x7eb52754 にモジュールがロードされていません。これを確認するために /proc/kallsyms ファイルからチェックしました。ソース ファイルへの 0x7eb5xxxx のマッピングを確認する方法は? システム上のこのデータはどこで入手できますか。
embedded - ハードウェア フロー制御を使用するように minicom を構成する
OMAP L138のハードウェア フロー制御を使用して UART 実装をテストするための支援を探しています。シリアル リンクのもう一方の端をエミュレートするために使用する実装をテストするためにminicom、どのように構成する必要があるかについての洞察を探しています。
OMAP から minicom に UART 経由でメッセージを送信する単純なアプリケーションがあります。これは、OMAP と minicom の両方がハードウェア フロー制御を使用しないように構成されている場合、期待どおりに機能します。ハードウェア フロー制御をオンにすると、minicom に出力が表示されません。
これが私が従ったステップのリストです:
- ハードウェア フロー制御を使用するように minicom を構成しました (Ctl AO で minicom シリアル ポート セットアップ メニューを開き、F でハードウェア フロー制御を有効にします)。
- を使用し
sttyて、rts/cts ハンドシェイクを有効にしstty -F /dev/ttyS1 crtsctsます。コマンドstty -F /dev/ttyS1 -aを使用して、crtscts が有効になっていることを確認できます。
上記の 2 つの変更により、端末プログラムと UART ドライバーでハードウェア フロー制御が有効になります。OMAP の UART も、ハードウェア フロー制御を使用するように構成されています。
ただし、上記の minicom への変更は、フロー制御を正しく機能させるには十分ではないようです。アプリケーションの起動後、OMAP からの RTS (送信要求) 信号が低くなり、minicom にデータを送信したいことを示します。適切に構成されている場合、minicom は OMAP の CTS (送信可) 信号を低くして、指定された受信バッファーのしきい値に達するまでデータの受け入れを開始する必要があります。これは起こりません。OMAP への CTS 入力は常にハイです。念のため、OMAP で RTS を CTS にショートさせてみましたが、予想通りのメッセージが minicom に表示されます! これは、2 つがどのように接続されているかを示すイメージです。

私が試したことから、minicom の設定方法に何かが欠けているようです。任意の提案をいただければ幸いです。
android - Pandaboard で Android の解像度を変更するには?
Pandaboard ES をターゲットとする AOSP から Android 4.2.1 をビルドしています。HDMI 出力で物理ディスプレイの解像度を 1920x1080 から 800x600 に変更する必要があります。
OMAP カーネル ソースから生成された .config のomapfb.mode=hdmi:800x600@60、omapfb.mode=800x600@60、またはvideo=omapfb:mode:800x600@60を追加しようとしましたが、そのたびに adb がデバイスを認識しなくなったようで、起動直後に「lsusb」コマンドから消えます。CONFIG_CMDLINEmake panda_defconfig
ありがとうございました。
linux-kernel - 組み込み: OMAP3 EVM ブート引数
私は初心者です。を使用してOMAP3 EVMいます。現在、経由で起動できますNFS。しかし、私はそれがしたいですSD card。boot.scrSDブートに変更しながらファイルを削除しました。正常に起動していました。ただし、この行の後、'Uncompressing Linux...'しばらく待ってから、ファイル システムが直接ロードされ、ログインを求められます。行の後に来ていた初期化ログの非常に多くの行'Uncompressing Linux...'が完全に欠落しています。しかし、ルート ファイル システムは完全にロードされており、以前と同じように使用できます。そこで、nfs関連の引数だけを取り除いてboot.scrファイルを作ってみました。
boot.scr以前のコマンドは、
今のboot.scrコマンドは、
を変更していませんuEnv.txt。その内容は、
これで、行の後に起動が完全に停止しました'Uncompressing Linux...'。私が間違っているところを教えてください。
beagleboard - BeagleBone GPIO 出力の PRU との同期 (TI AM335x)
AM335x の PRU ユニットの 1 つを使用して、BeagleBone の 4 つの GPIO ピン (GPIO1_2、GPIO1_3、GPIO1_6、GPIO1_7) を駆動しており、エッジ遷移を同期させたい (私の完全なソース コードは下部にあります)。
Beaglebone でピンの出力を HI に設定するには、対応するビットをアドレス 0x4804c194 で 1 に設定し、LO に設定するには、アドレス 0x4804c190 でビットを 1 に設定します。したがって、私の PRU アセンブリ コードは最初に出力 HI ビットを設定し、次に出力 LO ビットを設定します。
それぞれを実行するのに何サイクルかかるかにより、LO 期間は HI 期間よりも大幅に長くなります (50ns 対 110ns)。残念ながら、私は画像を投稿するには新しすぎるため、前のコードからのロジック アナライザーのスクリーンショットへのリンクを次に示します。
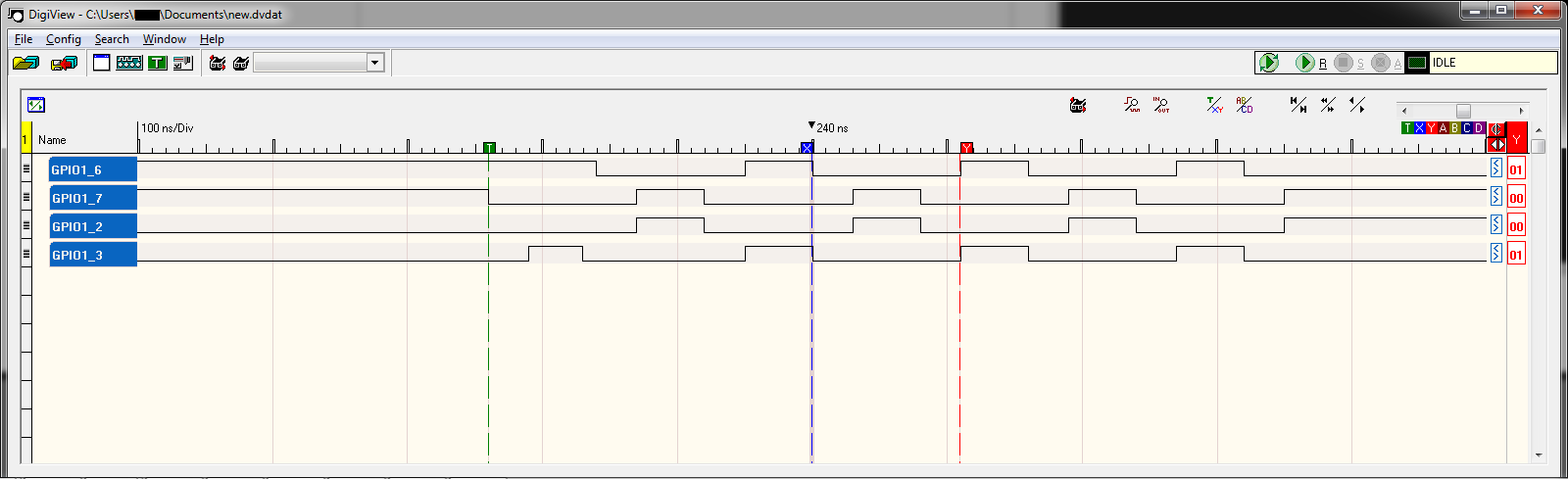{kind=link}
タイムアウトを均等にするために、HI ビットと LO ビットを交互に設定して、期間が 80ns で等しくなるようにしますが、HI と LO の遷移は互いに 80ns オフセットします。
ここにも、前のコードのロジック アナライザーのスクリーンショットがあります。
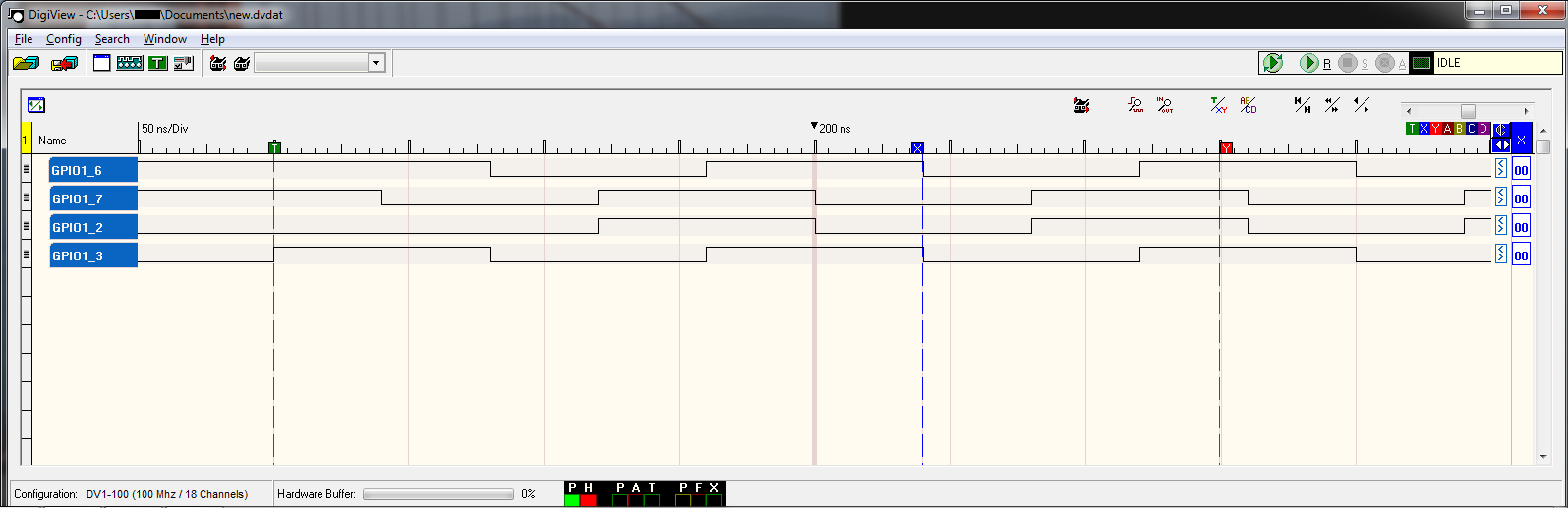{kind=link}
私の質問は、エッジ遷移を同時に発生させるにはどうすればよいですか? つまり、GPIO1_6 と GPIO_7 を比較すると、スクリーンショットの中央にあるのは、GPIO1_7 が LO に遷移したときに 200ns で、GPIO1_6 が HI に遷移する 50ns 前です。両方を同時に遷移させたいと思います。これを達成するために速度を落としてもかまいません。
ここに私のソースコードがあります:
ファイル: main.p
ファイル main.c:
ファイル main.hp: